Favorite This post is co-authored by Jackie Rocca, VP of Product, AI at Slack Slack is where work happens. It’s the AI-powered platform for work that connects people, conversations, apps, and systems together in one place. With the newly launched Slack AI—a trusted, native, generative artificial intelligence (AI) experience available
Favorite Today, we are excited to announce that Meta Llama 3 foundation models are available through Amazon SageMaker JumpStart to deploy and run inference. The Llama 3 models are a collection of pre-trained and fine-tuned generative text models. In this post, we walk through how to discover and deploy Llama 3
Favorite See CHANGELOG for latest features and fixes. You’ve likely experienced the challenge of taking notes during a meeting while trying to pay attention to the conversation. You’ve probably also experienced the need to quickly fact-check something that’s been said, or look up information to answer a question that’s just
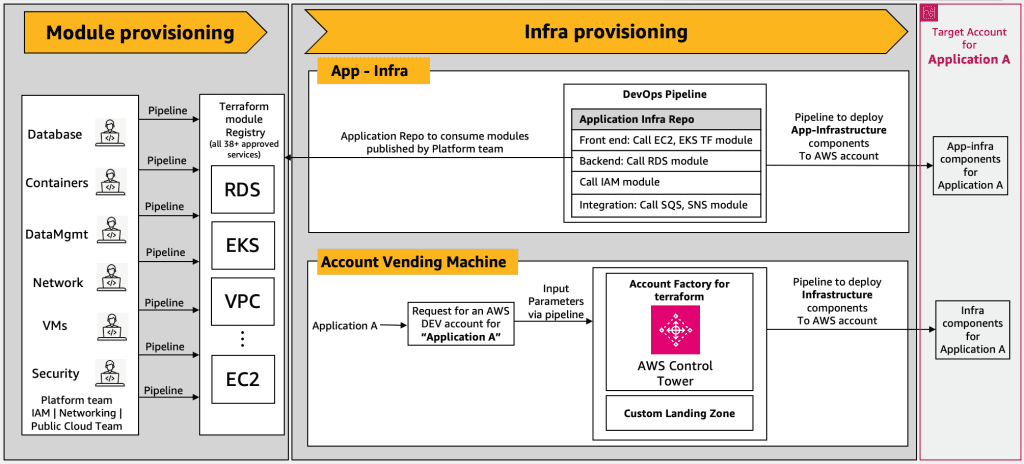
Favorite Migrating to the cloud is an essential step for modern organizations aiming to capitalize on the flexibility and scale of cloud resources. Tools like Terraform and AWS CloudFormation are pivotal for such transitions, offering infrastructure as code (IaC) capabilities that define and manage complex cloud environments with precision. However,
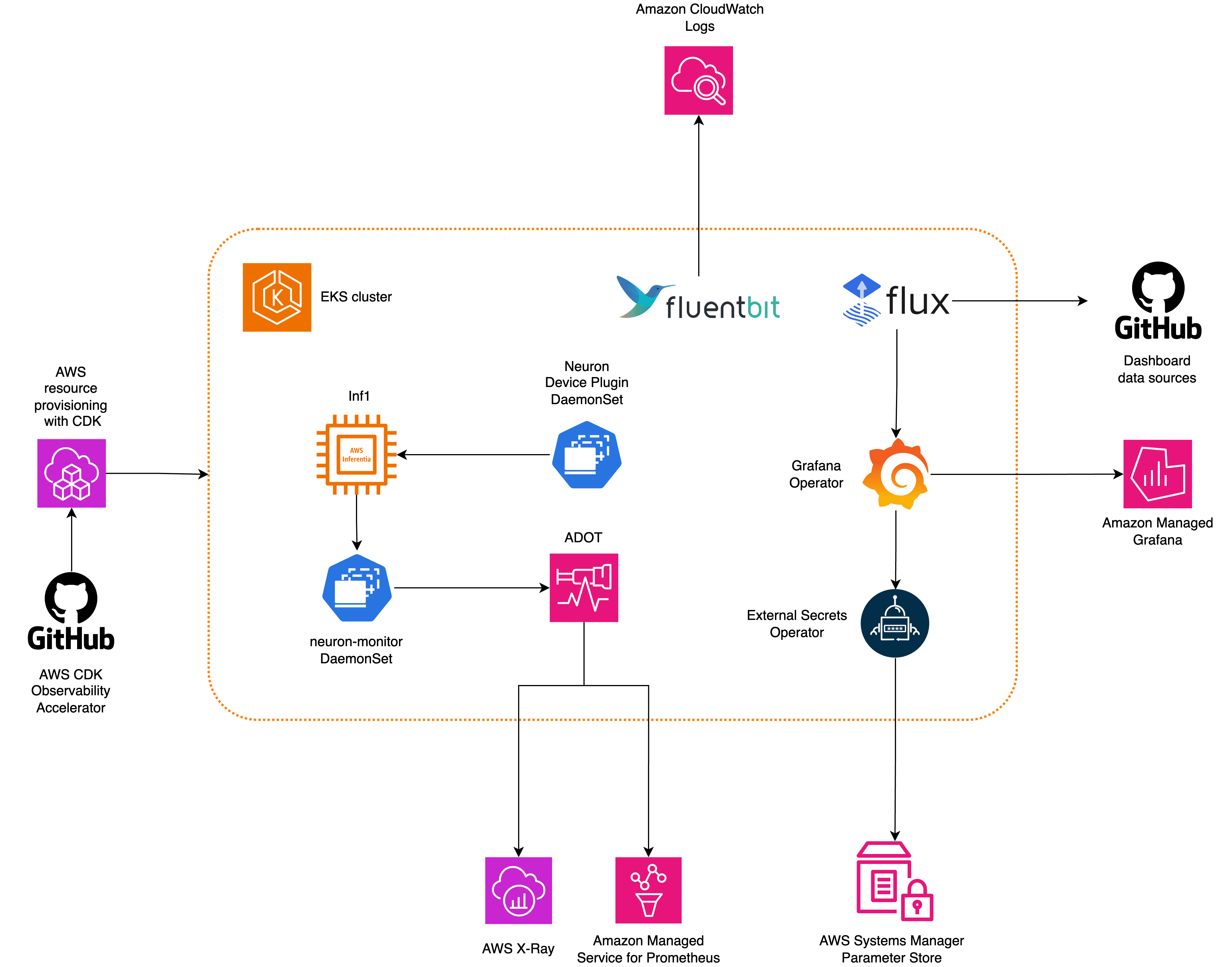
Favorite Recent developments in machine learning (ML) have led to increasingly large models, some of which require hundreds of billions of parameters. Although they are more powerful, training and inference on those models require significant computational resources. Despite the availability of advanced distributed training libraries, it’s common for training and
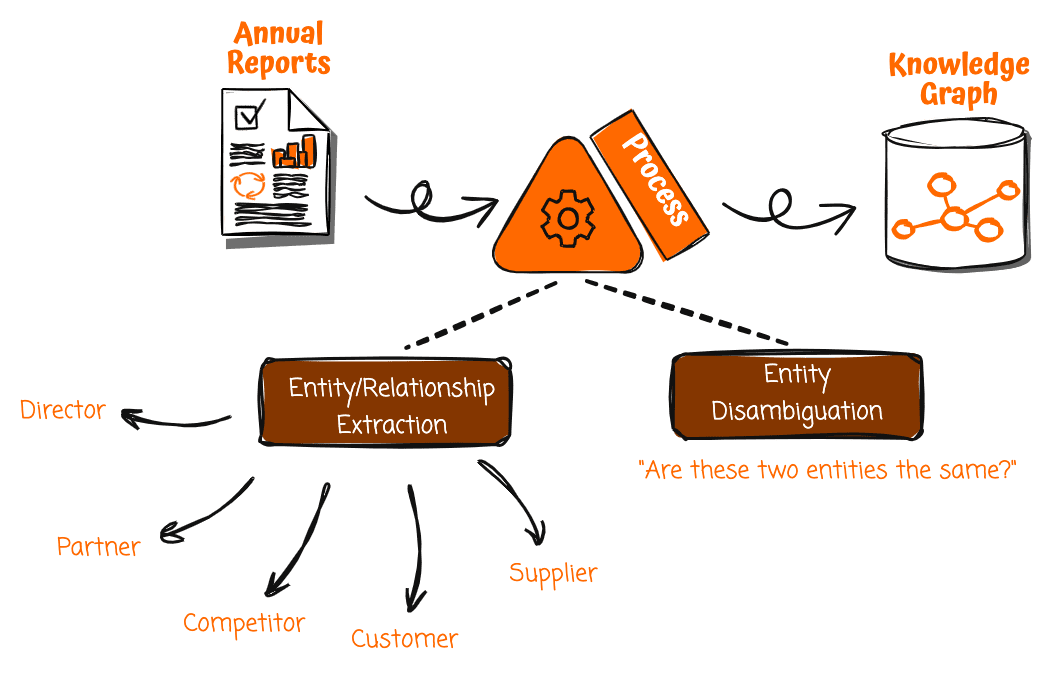
Favorite In asset management, portfolio managers need to closely monitor companies in their investment universe to identify risks and opportunities, and guide investment decisions. Tracking direct events like earnings reports or credit downgrades is straightforward—you can set up alerts to notify managers of news containing company names. However, detecting second
Favorite Generative artificial intelligence (AI) is transforming the customer experience in industries across the globe. Customers are building generative AI applications using large language models (LLMs) and other foundation models (FMs), which enhance customer experiences, transform operations, improve employee productivity, and create new revenue channels. FMs and the applications built
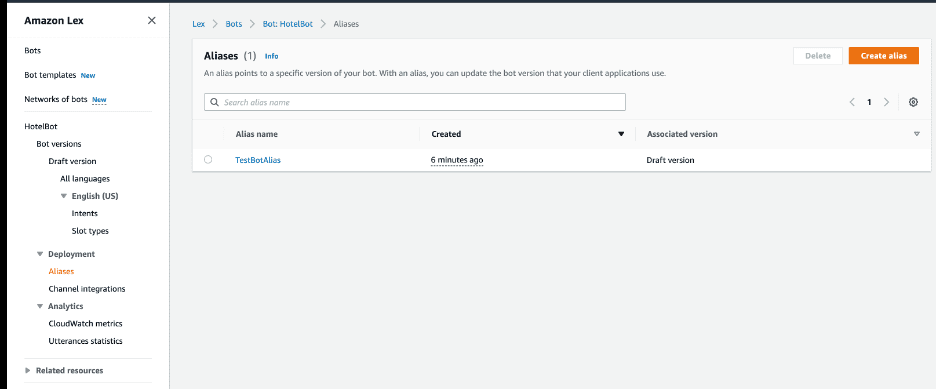
Favorite Amazon Lex is a fully managed artificial intelligence (AI) service with advanced natural language models to design, build, test, and deploy conversational interfaces in applications. It employs advanced deep learning technologies to understand user input, enabling developers to create chatbots, virtual assistants, and other applications that can interact with
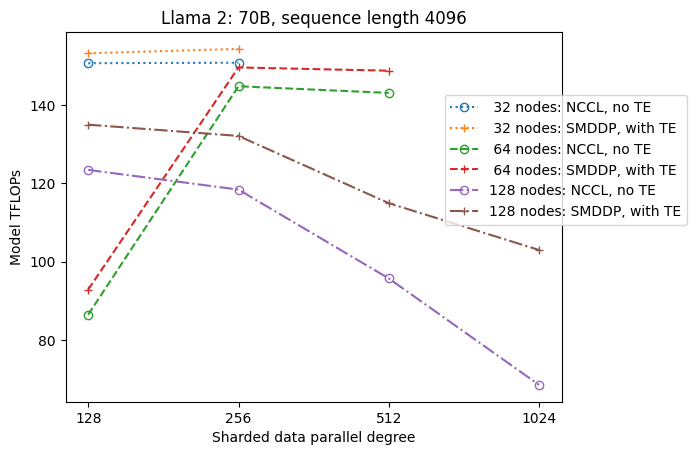
Favorite There has been tremendous progress in the field of distributed deep learning for large language models (LLMs), especially after the release of ChatGPT in December 2022. LLMs continue to grow in size with billions or even trillions of parameters, and they often won’t fit into a single accelerator device
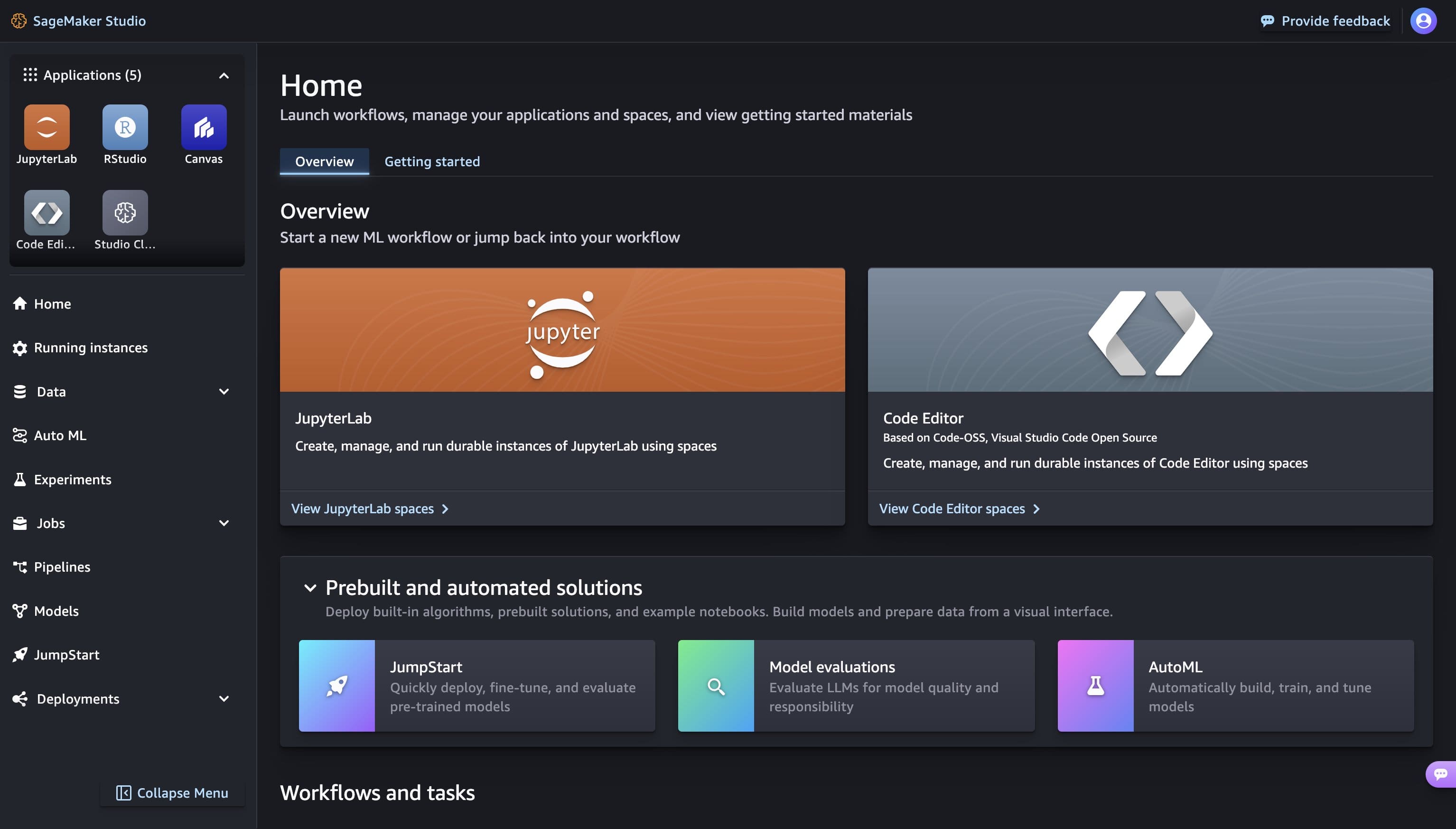
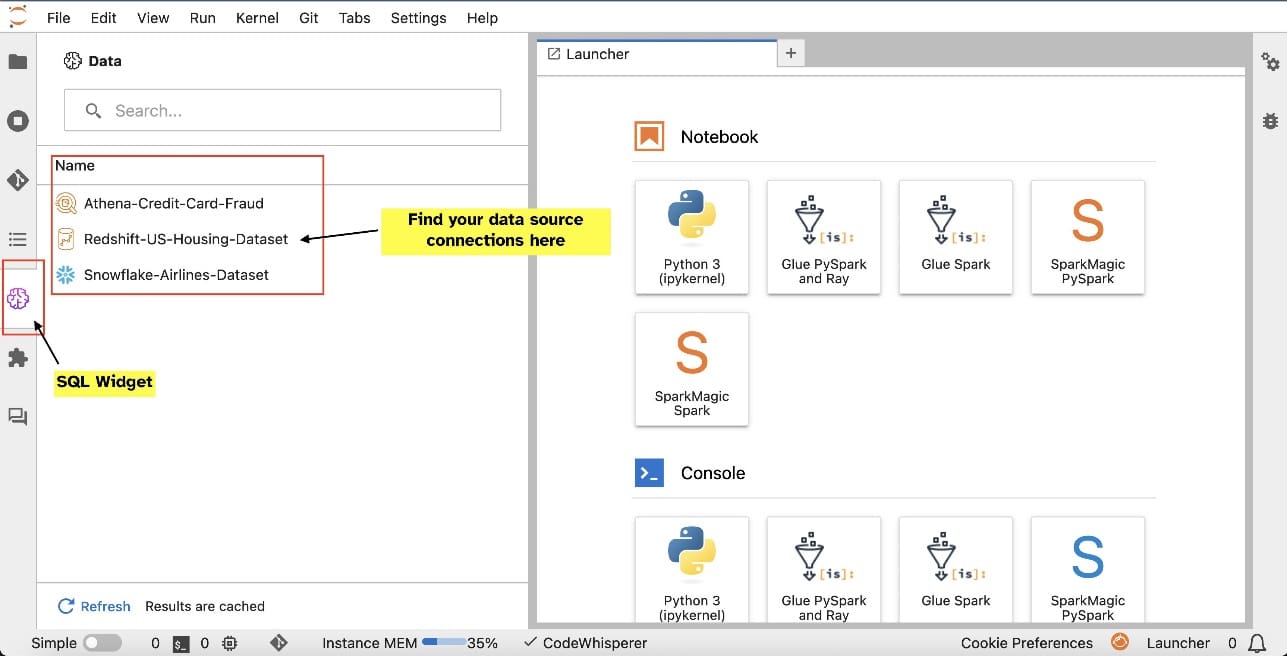
Favorite Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL