Favorite There is tension between copyright laws and large datasets suitable to train large language models. Common Corpus is a dataset that only uses text from copyright-expired sources to bypass the legal issues. It’s a useful achievement, paving the path to research without immediate risk of lawsuits. I also fear
Favorite Embeddings are integral to various natural language processing (NLP) applications, and their quality is crucial for optimal performance. They are commonly used in knowledge bases to represent textual data as dense vectors, enabling efficient similarity search and retrieval. In Retrieval Augmented Generation (RAG), embeddings are used to retrieve relevant
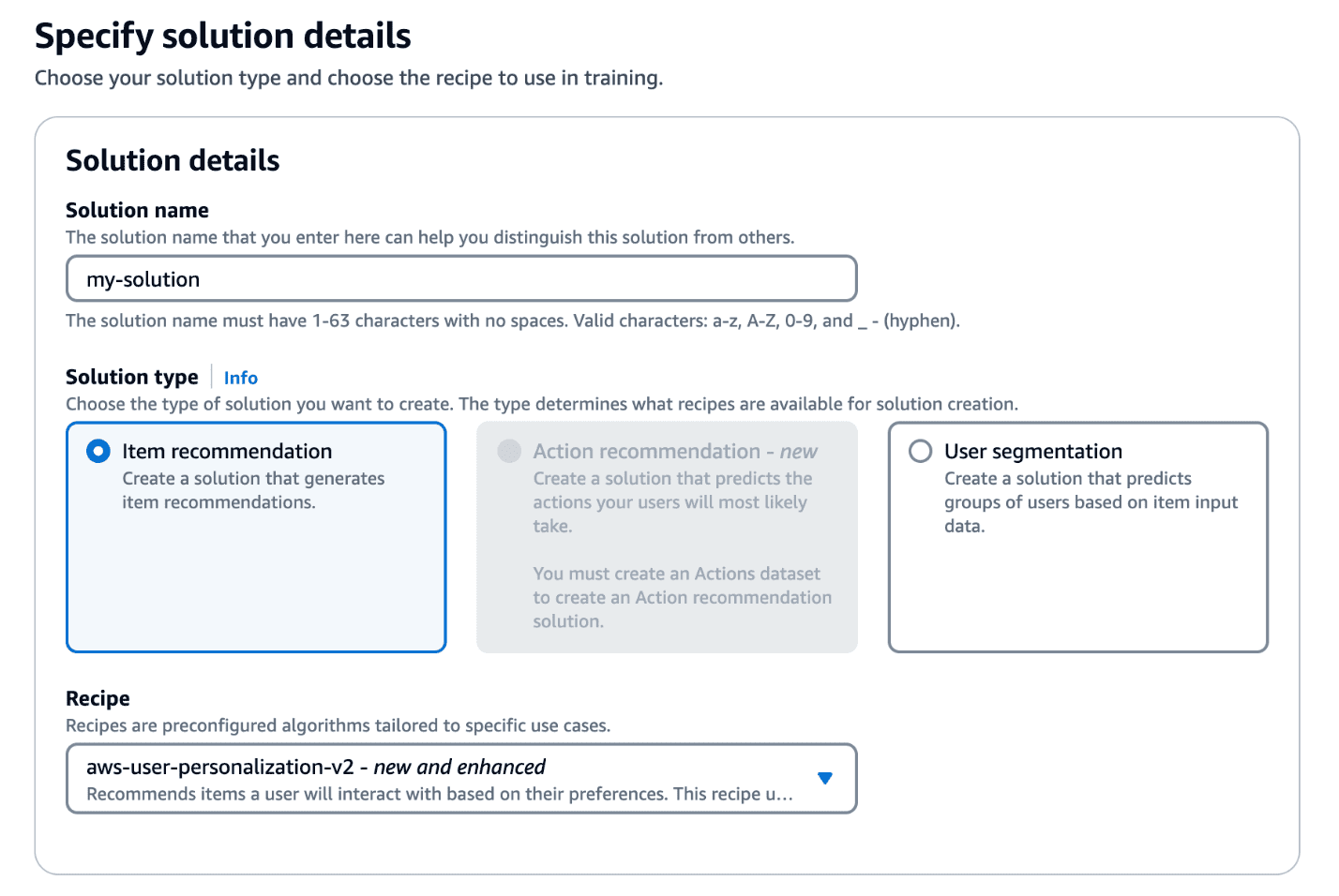
Favorite Personalized customer experiences are essential for engaging today’s users. However, delivering truly personalized experiences that adapt to changes in user behavior can be both challenging and time-consuming. Amazon Personalize makes it straightforward to personalize your website, app, emails, and more, using the same machine learning (ML) technology used by
Favorite As more powerful large language models (LLMs) are used to perform a variety of tasks with greater accuracy, the number of applications and services that are being built with generative artificial intelligence (AI) is also growing. With great power comes responsibility, and organizations want to make sure that these
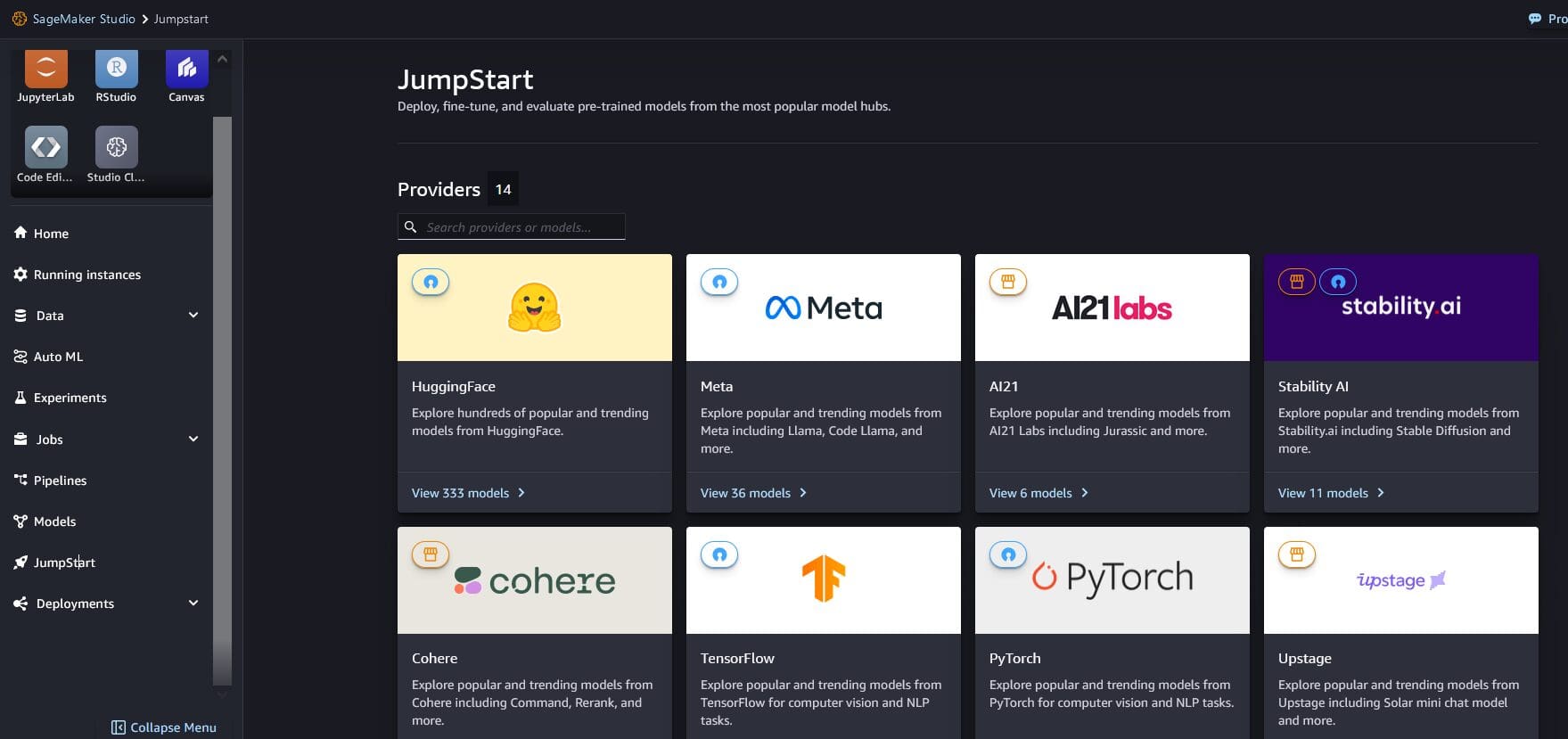
Favorite Today, we’re excited to announce the availability of Meta Llama 3 inference on AWS Trainium and AWS Inferentia based instances in Amazon SageMaker JumpStart. The Meta Llama 3 models are a collection of pre-trained and fine-tuned generative text models. Amazon Elastic Compute Cloud (Amazon EC2) Trn1 and Inf2 instances,
Favorite The European Commission recently published a public draft of the standards request associated with the Cyber Resilience Act (CRA). Anyone who wants to comment on it has until May 16, after which comments will be considered and a final request to the European Standards Organizations (ESOs) will be issued.
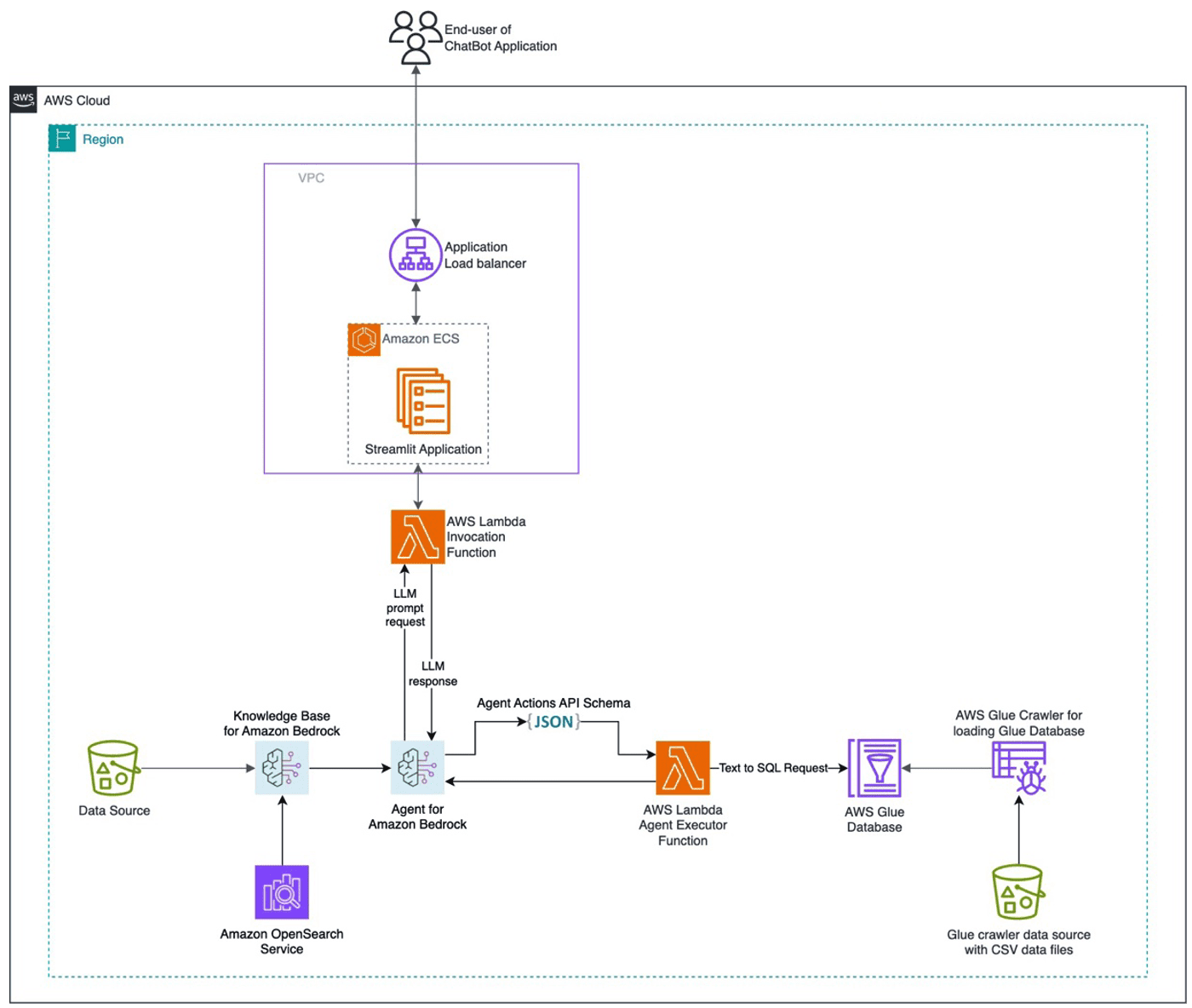
Favorite Numerous customers face challenges in managing diverse data sources and seek a chatbot solution capable of orchestrating these sources to offer comprehensive answers. This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. Amazon Bedrock is a fully
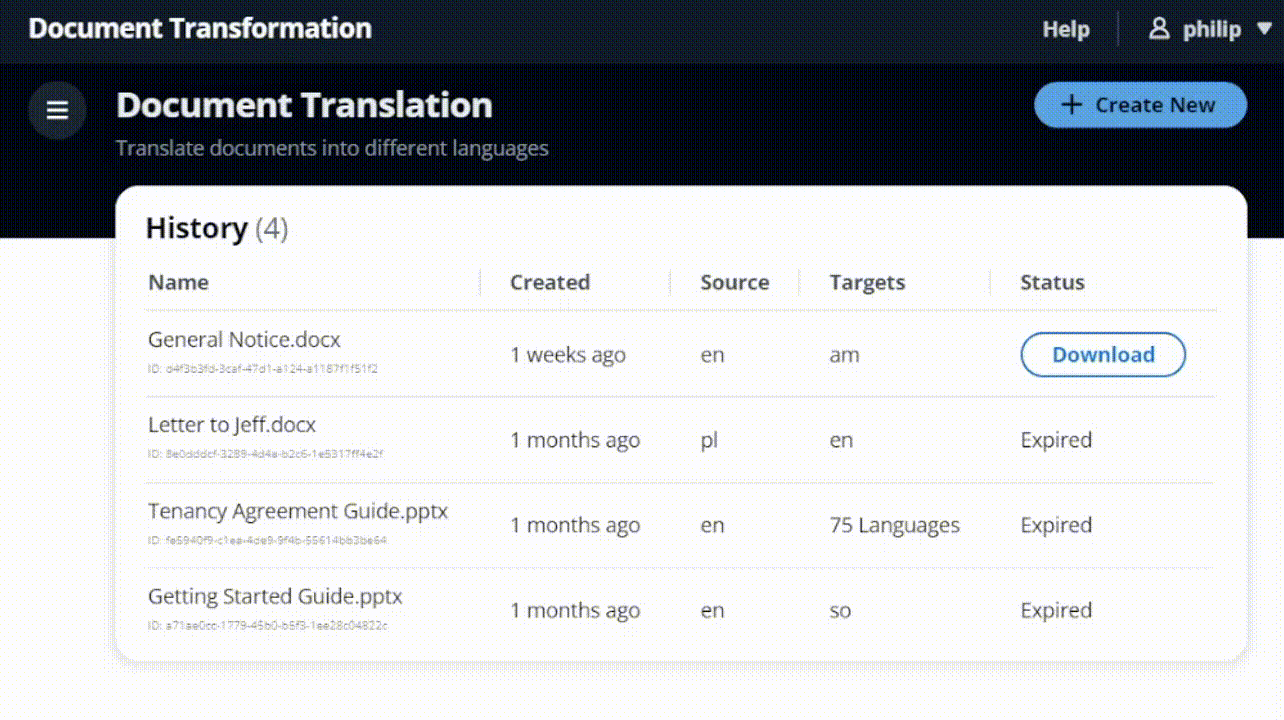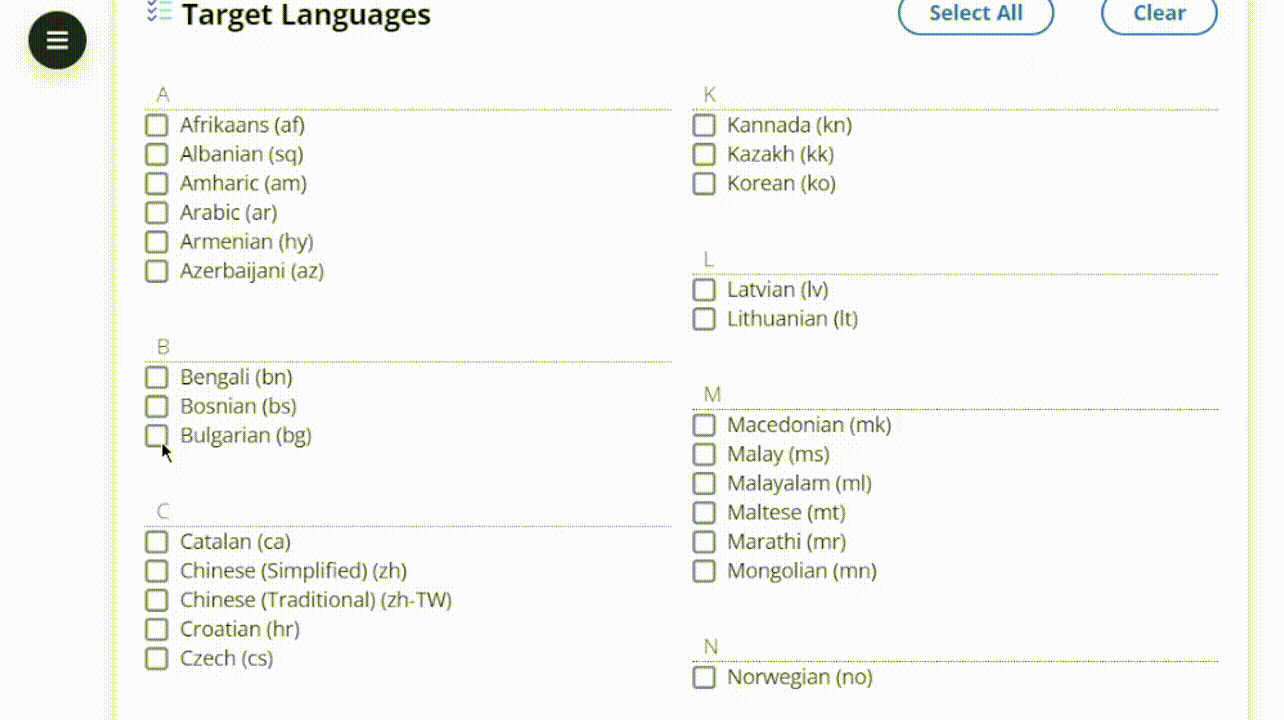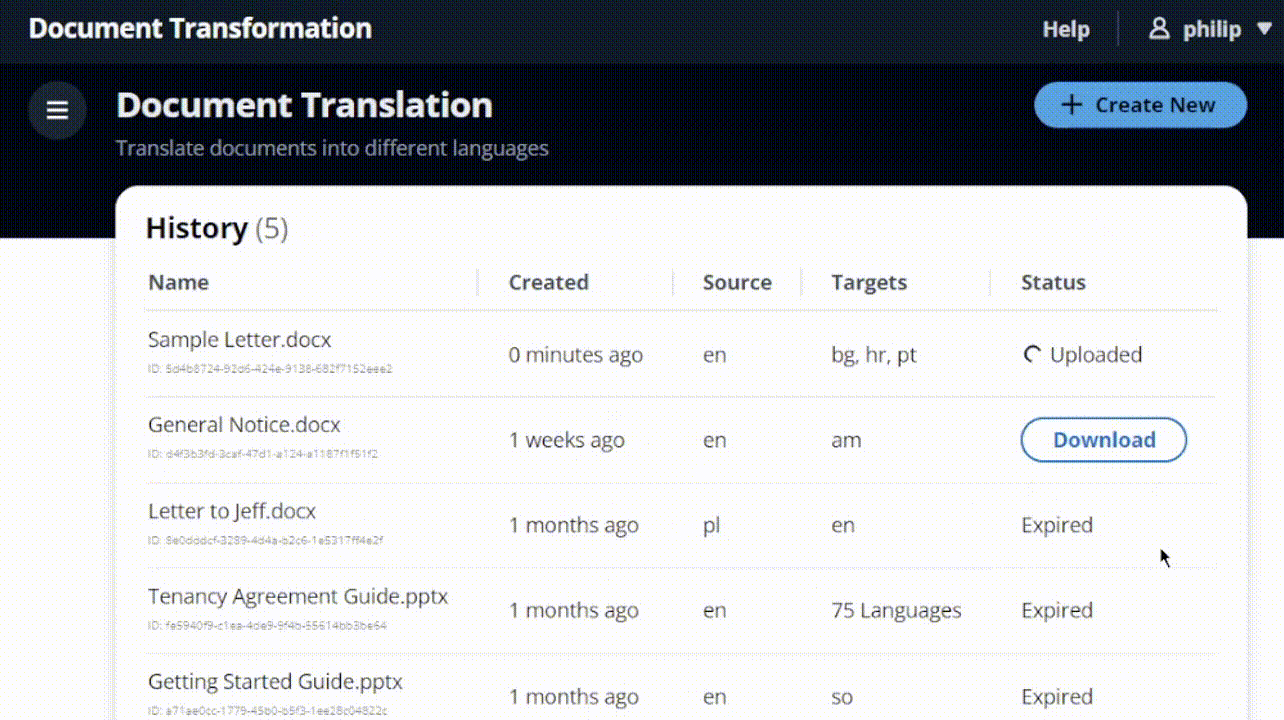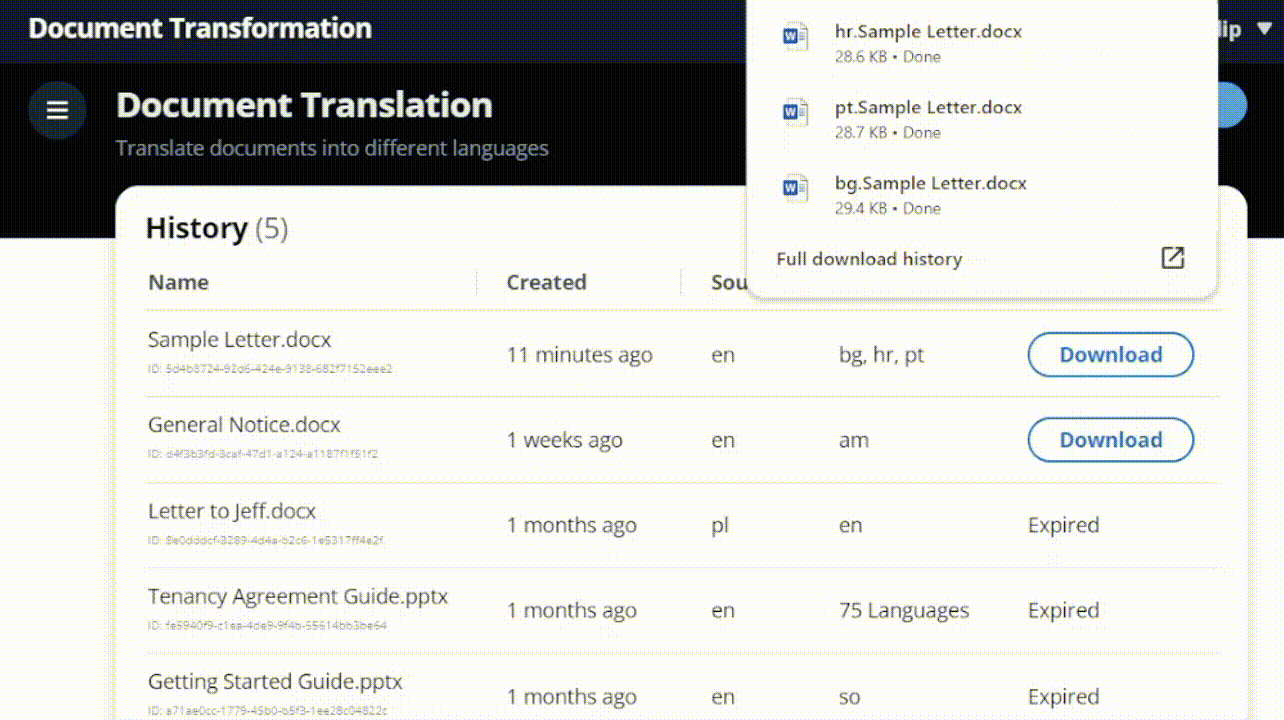
Favorite Organizations often offer support in multiple languages, saying “contact us for translations.” However, customers who don’t speak the predominant language often don’t know that translations are available or how to request them. This can lead to poor customer experience and lost business. A better approach is proactively providing information
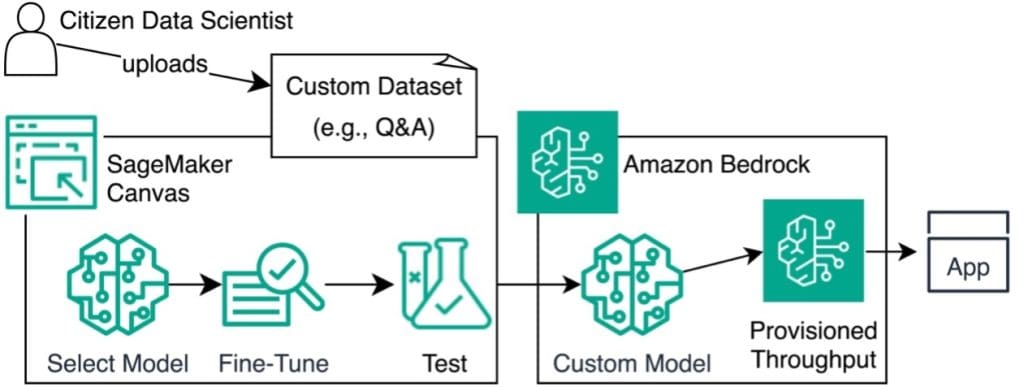
Favorite Imagine harnessing the power of advanced language models to understand and respond to your customers’ inquiries. Amazon Bedrock, a fully managed service providing access to such models, makes this possible. Fine-tuning large language models (LLMs) on domain-specific data supercharges tasks like answering product questions or generating relevant content. In
Favorite Large language models (LLMs) are making a significant impact in the realm of artificial intelligence (AI). Their impressive generative abilities have led to widespread adoption across various sectors and use cases, including content generation, sentiment analysis, chatbot development, and virtual assistant technology. Llama2 by Meta is an example of